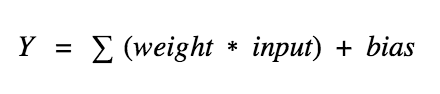#41 Técnicamente eso es una ANN (Artificial Neural Network), más que una IA. Te cuento lo que sé, que estoy aprendiendo sobre el tema últimamente. Que alguien me corrija si digo algo incorrecto:
Te comento: lo de la izquierda son los input nodes, que funcionan como parámetros de entrada. Estos datos se extraen de algún lado, véase una base de datos, un .csv, un .txt... durante la fase de entrenamiento de la ANN, lo que se hace es proporcionarle un parámetro extra (la variable dependiente) que es la que dicta si cada una de esas filas ha tenido una cardipatía o no. Entonces, la IA cogerá todas las variables de entrada y tratará de sopesar cuáles son más importantes, cómo están relacionadas, y determinar para qué mezcla de variables habrá una cardiopatía o no.
En la fase de entrenamiento, se puede pasar cada fila o conjunto de filas (batch training) a la ANN y dejarle a ella sola que sopese qué variables son las más importantes. Eso es lo que sucede en las Hidden Layers, que en este caso sólo hay una (compuesta de los nodos H1:H3). Lo que hacen estos nodos es recibir las "conexiones" de los anteriores filtradas por un "nivel de importancia" (o también llamado "peso de variable). Al principio determina pesos aleatorios y, simplemente, va probando. Cuando llega a la capa final, hay una función de coste que compara el resultado de la variable dependiente proporcionada a mano, con el resultado que la máquina cree que es. Dependiendo del resultado, se produce una operación de backpropagation que varía los pesos ligeramente dependiendo de lo que haya aprendido en cada iteración. Repite miles de veces, y la IA sabrá realmente bien qué pesos debe tener cada conexión.
Cada nodo también ejecuta una función de activación, y desconozco cuáles serán en estos casos pero para una fully connected network como esta me imagino que usará ReLU (rectifier function), pero hay varias funciones de activación cuyo trabajo es determinar si una neurona dada de las hidden layers debe ser disparada. Esto se va haciendo a lo largo de las capas ocultas, haciendo que las neuronas apliquen esta función una tras otra, y propagando el resultado de éstas hacia la output layer será lo que nos otorgue un resultado concreto. Los outputs de estas funciones de activación dependen de la función usada (tanh, sigmoid, ReLU, softmax...). A su vez, una neurona también almacena un bias a lo largo de su entrenamiento que también supondrá un parámetro de dicha función de activación.
Cuando ya está entrenada la red neuronal, se puede usar para predecir un resultado (es decir, picar ella misma la variable dependiente) de una nueva fila de datos. Como sabe qué variables son más importantes (a través de los pesos definidos en las conexiones entre nodos), y cómo cotejarlas, termina ofreciéndonos por la output layer el resultado final.
Cabe decir que los datos necesitan previamente un cierto preprocesamiento que hace que incluso cuando están en la input layer, son ya irreconocibles para el ser humano, y que como dice #43, no puedes saber con exactitud cómo funcionan las hidden layers ya entrenadas; es una caja negra donde el flujo de información está tan transformado, que no hay forma de saber bien qué sucede ahí. Pero vaya que estas cosas suelen funcionar terriblemente bien.


 .
.