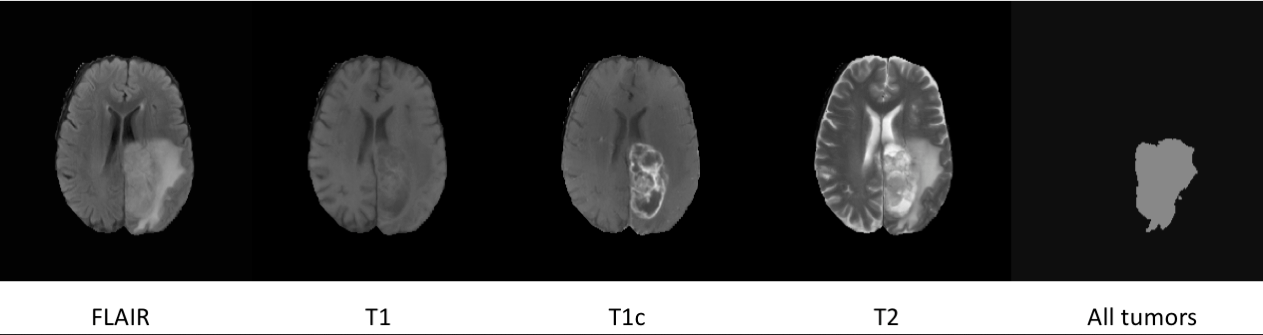
#120 Lo puse creo que demasiado rapido y ahora con otros ojos veo que no se entiende.
La red tiene por decirlo asi 2 caminos que a su vez cada camino se divide en 3 subcaminos. Vale pues si intentaba implementar toda la red se me quedaba el jupyter con el asterisco pillado y eso no cambiaba en horas asi que decidi coger el camino que parace una U-NET( Este tipo de red se llama asi xk la entrada tiene el mismo shape que la salida, donde vas bajando buscando caracteristicas, y luego subes otra vez)
Este camino tiene los 3 ramales de los que hablaba donde las convoluciones son en cada camino de forma diferente hasta que acaban en [nºbatches,30,30,4] luego las fusiono y bajo hasta 15x15 y de ahi vuevlo a ir subiendo hasta que tenia la misma entrada. La cosa es que cuando lo probé mis muestras eran 45, el numero de batch es 15 asi que 45/15 = 3 y num epochs es uno.
Obviamente solo doy una vuelta con 3 pasos y eso divergia, y veo que tengo que cambiar estos numeros pero en que proporciones?? Mayor numero de muestras, disminuir el tamaño de batch, aumentar los epochs?
Lo siento por el tochopost xD